쉽지 않다...
# KNN dataset
np.random.seed(12)
n_classes = 4
n_features = 2
n_data = 100
low = 0
high = 50
centroid = np.random.uniform(low, high, size=(n_features, n_classes))
K = 5
# class dataset
class_data = np.hstack([class_idx * np.ones(n_data,) for class_idx in range(n_classes)])
class_data = class_data.reshape(-1, 1)
# Target data
tmp_data_scale = 2
target_data = np.vstack([np.random.normal(centroid[:, i], tmp_data_scale, size=(n_data, n_features)) for i in range(n_classes)])
# print(target_data.shape) # (n_data*n_classes, n_features)
# function to concatenate data sets
def concat_set(ndarray1, ndarray2):
return np.concatenate((ndarray1, ndarray2), axis=1)
# function to return the index K
def get_index_K(ndarray1):
e_dist = np.linalg.norm((ndarray1 - target_data), axis=1).reshape(-1, 1)
K_idx = np.argsort(e_dist, axis=0)[:K]
return K_idx
# function to calculate euclidean distance between samples <-> dataset
def predict_class_by_K_idx(k_idx):
uniques, cnts = np.unique(class_data[k_idx], return_counts=True)
claxx = int(uniques[np.argmax(cnts)])
return claxx
# test sample
# sample_data = target_data[258]
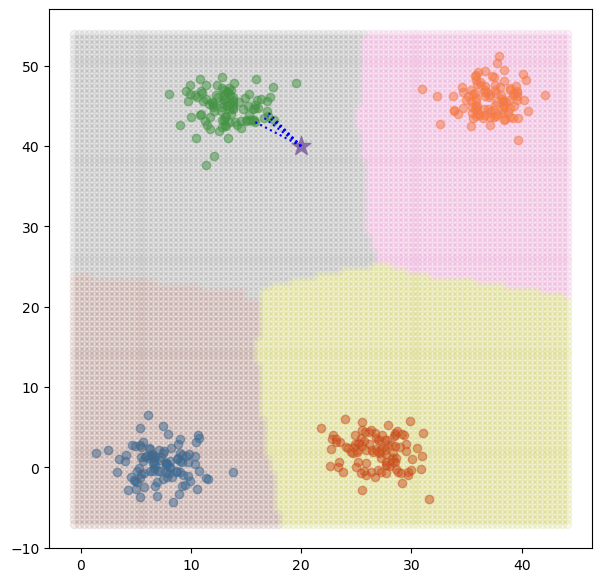
sample_data = np.array([20, 40])
# print(f'sample predict class : {predict_class_by_K_idx(get_index_K(sample_data))}')
fig, ax = plt.subplots(figsize=figsize)
for idx_class in range(n_classes):
ax.scatter(dataset[idx_class*n_data:(idx_class+1)*n_data,0], dataset[idx_class*n_data:(idx_class+1)*n_data,1], alpha=0.5)
ax.scatter(sample_data[0], sample_data[1], marker='*', s=200) # type: ignore
# meshgrid
xmin, xmax = ax.get_xlim()
ymin, ymax = ax.get_ylim()
xmesh, ymesh = np.meshgrid(np.linspace(xmin, xmax, n_data), np.meshgrid(np.linspace(ymin, ymax, n_data)))
meshset = concat_set(xmesh.reshape(-1, 1), ymesh.reshape(-1, 1)) #(n_data^2, 2)
# init mesh[2] = 0
zeroset = np.zeros(n_data**2).reshape(-1, 1)
meshset = concat_set(meshset, zeroset) #(n_data^2, 3)
# predict class of meshset
for mesh in meshset:
mesh[2] = predict_class_by_K_idx(get_index_K(mesh[:n_features]))
# scatter meshset by class
for idx_class in range(n_classes):
ax.scatter(meshset[meshset[:, n_features]==idx_class, 0], meshset[meshset[:, n_features]==idx_class, 1], alpha=0.1)
# plot nearest
K_nearest_idx = get_index_K(sample_data)
for k_idx in K_nearest_idx.flatten():
ax.plot([sample_data[0], target_data[k_idx,0]], [sample_data[1], target_data[k_idx,1]], ls=':', c='b')
'새싹 > TIL' 카테고리의 다른 글
| [핀테커스] 231020 Gaussian Naive Bayes - iris 실습 (1) | 2023.10.20 |
|---|---|
| [핀테커스] 231019 Bayes Theorem - 실습 (0) | 2023.10.20 |
| [핀테커스] 231010 KNN 구현 (0) | 2023.10.10 |
| [핀테커스] 231006 matplot - iris (0) | 2023.10.06 |
| [핀테커스] 231005 matplot 실습 (0) | 2023.10.05 |