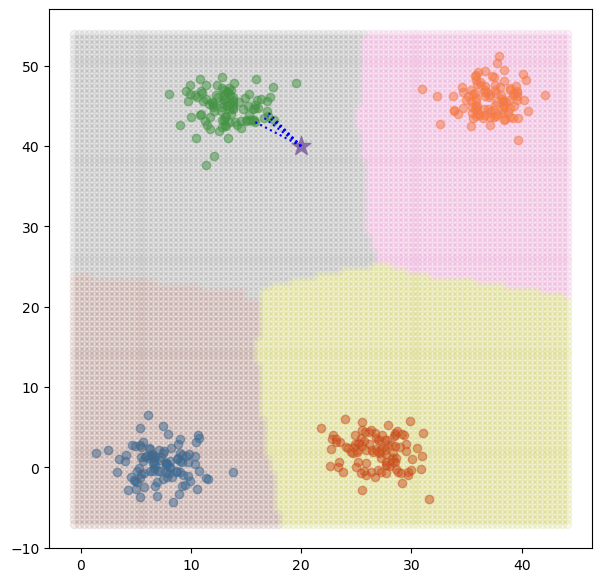
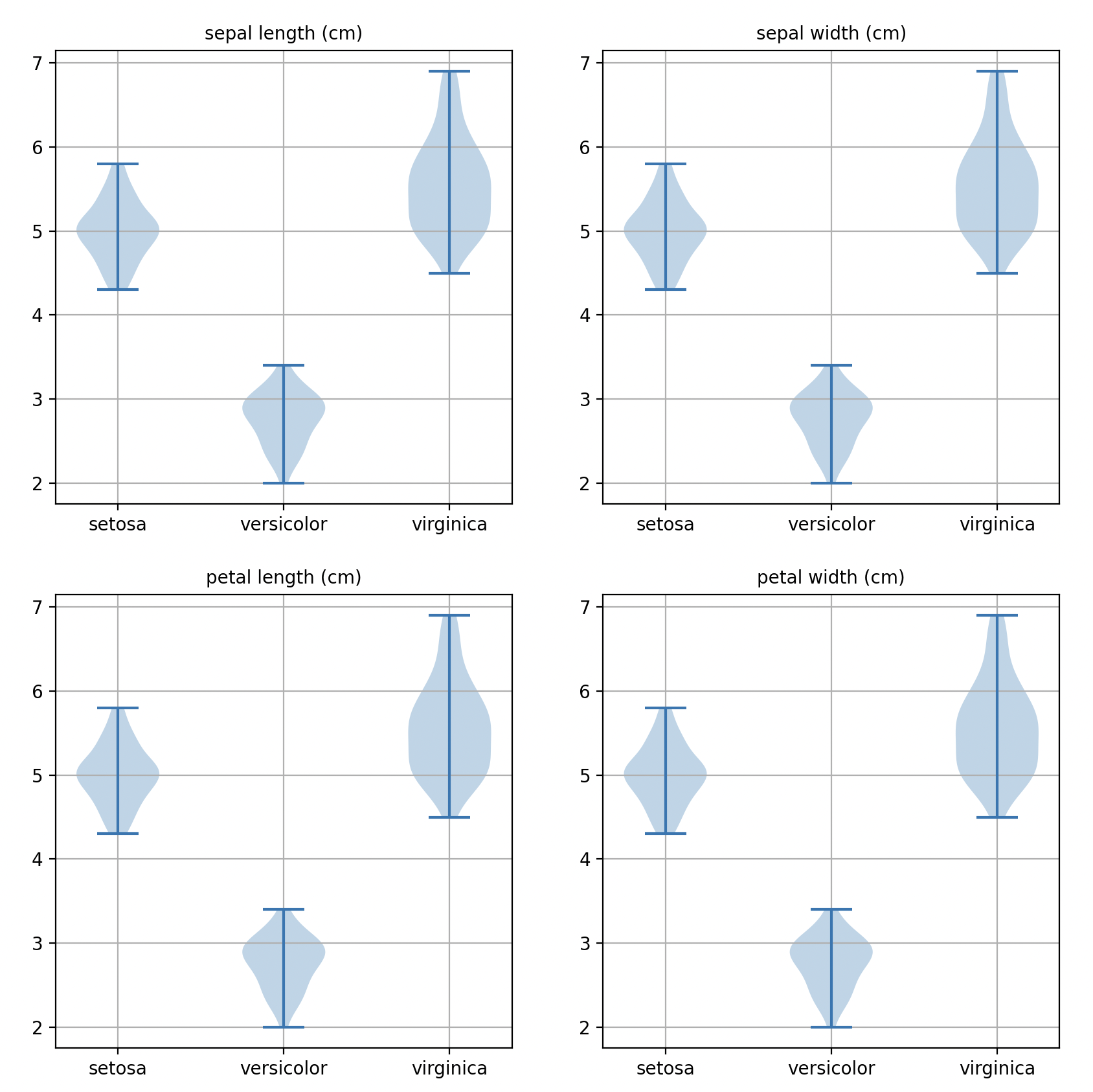
import matplotlib.pyplot as plt from sklearn.datasets import load_iris import numpy as np import pandas as pd import matplotlib.pyplot as plt import math # 확률밀도함수 := likelihood def likelihood(x, u, s): p = 1 / math.sqrt( 2 * math.pi * math.pow( s, 2 )) * math.exp( - math.pow( x - u, 2) / ( 2 * math.pow( s, 2) ) ) return p # 데이터 불러오기 iris = load_iris() iris_X, iris_y = iris.data, iris.target # ty..