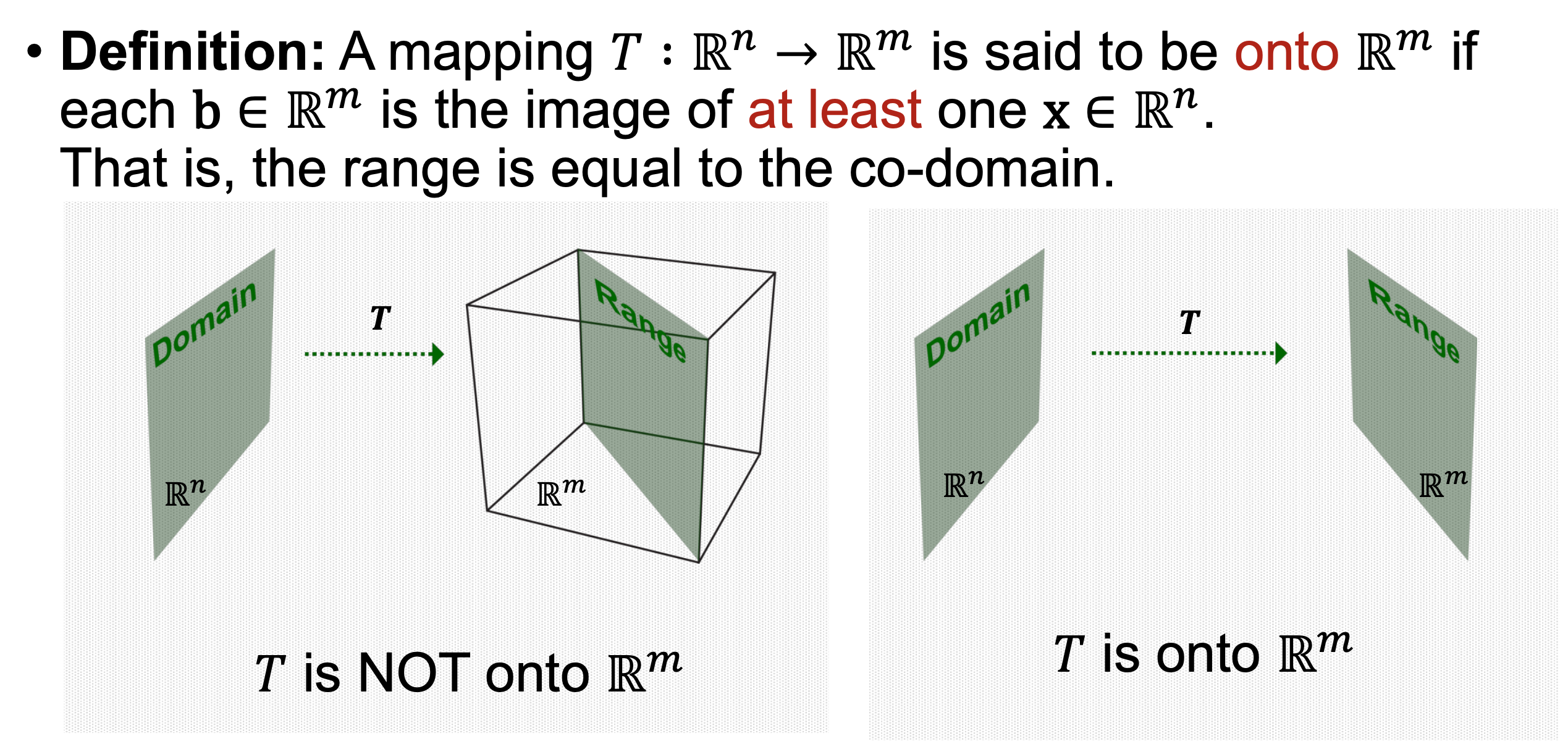
이 글은 proxmox 구축 전 상태에서 Gemini와 검토한 자료입니다. 추후 테스트 후 업데이트 예정입니다.1. 아키텍처 개요 (Architecture)목표운영/개발 서버(Proxmox)가 랜섬웨어에 의해 모든 데이터가 암호화되더라도 서비스 정상화.백업 서버(PBS) 자체가 공격당해도 시놀로지 계층에서 방어.구성도Source: Proxmox VE (운영/개발 VM + 호스트 설정)Backup Server: Synology NAS VMM(Virtual Machine Manager) 위에 설치된 Proxmox Backup Server (PBS)Last Line of Defense: Synology Snapshot Replication (PBS VM 이미지를 보호) Proxmox는 PBS에 백업을 Push..